Die Verwendung von JavaScript zur Darstellung von Inhalten war im Zusammenhang mit SEO lange problematisch. Früher konnten Suchmaschinen noch überhaupt keine Skripts ausführen. Seitdem hat sich die Situation wesentlich entschärft. Die Crawling- und Indexierungsdienste von Google sind heute prinzipiell auf dem gleichen Stand wie die jeweils aktuelle Chrome-Version. Was also im Chrome dargestellt werden kann, ist grundsätzlich auch indexierungsfähig. Aber crawlt Google tatsächlich nur HTML-Links?
JavaScript-Links und Google
Nach wie vor besonders problematisch für Suchmaschinen sind aber JavaScript-Links. An der Entwicklerkonferenz I/O hat Google letztes Jahr klar gemacht, dass sie nur HTML-Links crawlen. Genauer gesagt: Nur wenn ein Anchor-Tag (<a>) zusammen mit einem href-Attribut inkl. URL als Wert auftritt, handelt es sich um einen Link, der von Google gecrawlt wird. Beispielsweise werden Links, die ausschliesslich über eine Onclick-Funktion gesteuert werden, nicht gefolgt.
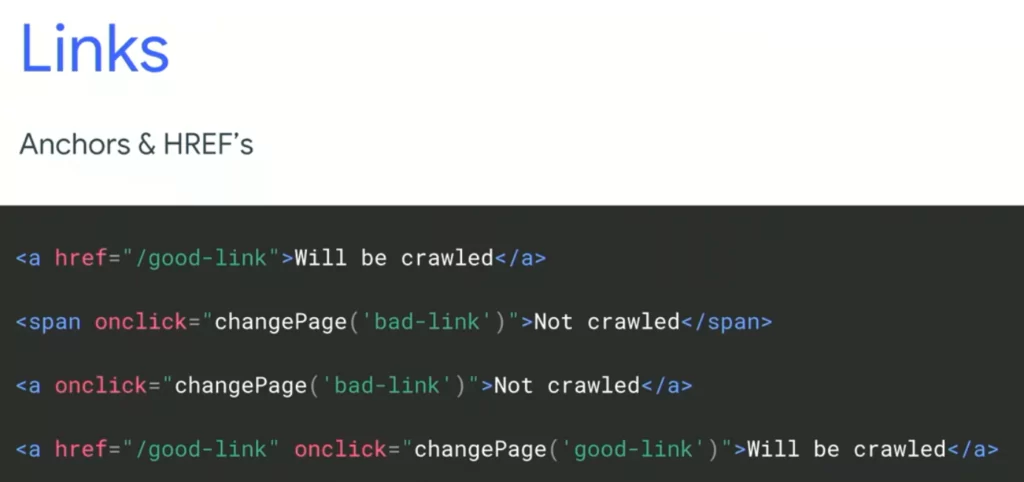
Auch auf support.google.com unter dem Titel Make your links crawlable liest man, dass Google nur HTML-Links crawlt.
Das lässt aufhorchen. Denn viele Links draussen im Web entsprechen diesen Anforderungen nicht, insofern sie beispielsweise ausschliesslich auf einer onclick-Funktion basieren. Wir wollten es daher genauer wissen, und nicht nur auf diese, vielleicht zu vereinfachenden, Aussagen von Google vertrauen.
Um zu prüfen, ob Google tatsächlich nur HTML-Links crawlt, haben wir eine Testseite aufgesetzt. Die URL unserer Startseite haben wir Google über die Search Console und über Backlinks mitgeteilt. Auf der Startseite haben wir eine Reihe von Links (HTML und JS) zu Unterseiten implementiert, die nirgendwo anders verlinkt sind. Anhand der Server Logs (November 2018 – September 2019) konnte schliesslich nachvollzogen werden, welche der Unterseiten von den Crawlern besucht wurden. Woraus sich wiederum ergab, welchen Links gefolgt wurden.
Auf einen kleinen Vorbehalt gegenüber dem Test-Setup muss hingewiesen werden: Ein Besuch einer Seite muss in diesem Setup nicht in jedem Fall mit dem Folgen des entsprechenden Links einhergehen. Schliesslich hätte die Suchmaschine die entsprechende URL der Unterseite auch aus dem Code «extrahieren» können, ohne tatsächlich dem Link zu folgen, d. h. ohne die entsprechende JS-Funktion auszuführen. Das konnten wir nicht prüfen.
Die Resultate im Überblick
Google crawlt tatsächlich, anders als offiziell verlautbart, auch gewisse JS-Links. Aus unserem Test geht hervor, dass noch nicht einmal die Verwendung eines Anchor-Tags notwendig ist. Google crawlt insbesondere auch <div>-Elemente. Allerdings gelten andere Restriktionen:
- Google crawlt insbesondere keine
<button>-Elemente.
- Der JS-Code muss im (client- oder serverseitig erstellten) HTML vorhanden sein. Links basierend auf externen Skripts wurden nicht gecrawlt, obwohl diese Dateien dem Crawler zugänglich waren und bestimmte Anweisungen in der gleichen Datei nachweislich durch den Renderingservice von Google ausgeführt wurden.
Einige dieser Erkenntnisse wurden übrigens auch in einem früheren JavaScript-SEO-Test von Merkle gewonnen.
Obwohl Google unter bestimmten Bedingungen JS-Links crawlt, sehen wir das nicht als Freigabe, auf die Verwendung von HTML-Links (mit Anchor-Tag und href-Attribut) zu verzichten! Wir raten im Rahmen unserer SEO-Beratung in jedem Fall, mindestens als Backup für die Crawler, HTML-Links zu verwenden. Dies aus zwei Gründen:
- Es ist, trotz unseren Testergebnissen, einfach sicherer, wenn man sich auf die offiziellen Aussagen von Google verlässt.
- Es ist unklar, ob JS-Links, auch wenn sie gecrawlt werden, gleichermassen in den Rankingalgorithmus eingehen.
Was aber ganz klar nicht (mehr) möglich ist: Die Crawler davon abzuhalten, bestimmte Bereiche der Seite zu crawlen, indem JS-Links verwendet werden. Dazu sollte unbedingt auf die robots.txt zurückgegriffen werden oder auf Nofollow-Direktiven.
Der Testaufbau
In unserem Test haben wir JavaScript-Links verwendet, die auf reinem (Vanilla) JavaScript basieren und solche, die auf der populärsten JS-Bibliothek jQuery aufbauen.
In einigen Fällen haben wir die JS-Methode window.open (öffnet ein neues Browser-Fenster) verwendet, um den Aufruf einer Unterseite zu provozieren. Daneben haben wir auf window.location.href und window.location.replace zurückgegriffen, welche den aktuellen Zustand des Browsers, d. h. die aktuell geöffnete URL, verändern. Window.location.href fügt der Browser-History einen neuen Eintrag hinzu, wie das normalerweise bei Links der Fall ist. Window.location.replace überschreibt den aktuellen Eintrag, ein Zurück im Browser ist in diesem Fall nicht möglich.
Aus reiner Neugier haben wir zusätzlich auch window.history.replaceState verwendet. Damit wird kein Wechsel auf eine neue Seite herbeigeführt. Es wird keine neue Anfrage an den Server gesendet, sondern nur die Browser-History manipuliert. Völlig überraschend ist Google diesem «Link», der eigentlich keiner ist, gefolgt! (Diese Möglichkeit, die Browser-History zu manipulieren, ist übrigens wichtig, wenn es um SEO für One-Page-Webseiten geht, wie wir hier in unserem Blog dargestellt haben.)
Als Auslöser haben wir einfache Klick-Funktionen verwendet. Beispiel:
$(document).ready(function(){
$("#ID").click(function(){
window.location.href = "URL";
});
});
Den entsprechenden JS-Code haben wir in externen Dateien zur Verfügung gestellt, in die HTML-Datei eingefügt und in einigen Fällen auch direkt innerhalb des Anchor-Tags oder sogar innerhalb des href-Attributs des Links platziert. Beispiele für die letzteren beiden Fälle:
<a href="javascript:void(0);" onclick="window.location.href='URL'">Anchortext<a/>
<a href="javascript:window.location.href='URL'">Anchortext<a/>
<a onclick="window.location.href='URL'">Anchortext<a/>
Wie anhand des letzten Beispiels ersichtlich ist, haben wir manchmal auf ein href-Attribut verzichtet. Zudem haben wir auch «Links» ohne Anchor-Tag getestet: Stattdessen haben wir Divs (<div>), <p>-Elemente und Buttons (<button>) verwendet. Insbesondere die Verwendung von letzteren ist relevant, weil es immer wieder vorkommt, dass Buttons als Links «missbraucht» werden.
Schliesslich haben wir auch normale HTML-Links getestet, die allerdings clientseitig gerendert werden müssen, also erst über das Ausführen von JavaScript auf dem Client erstellt werden (via document.createElement('a')). Wie erwartet hatte Google damit keine Mühe. Clientseitiges Rendering ist heute für Google höchstens noch in komplexeren Fällen ein Problem. Allerdings wurde der clientseitig gerenderte Link erst 4 Tage nach dem ersten Besuch durch den Googlebot gecrawlt. Alle anderen gecrawlten Links wurden sofort nach dem ersten Besuch ein erstes Mal gecrawlt. Das ist konsistent mit dem bekannten Umstand, dass es ab dem Zeitpunkt des ersten Crawlings jeweils einige Tage dauern kann, bis Google Inhalte indexiert, die clientseitig gerendert werden müssen.
Ein näherer Blick auf die Resultate
Bei der Verwendung von Vanilla JS und jQuery sahen wir keine Unterschiede. Ebenfalls als irrelevant herausgestellt hat sich die Frage, ob window.open, window.location.replace oder window.location.href verwendet wird. Und schliesslich spielte es keine Rolle, ob ein href-Attribut verwendet wurde. Relevant ist hingegen die Vertaggung des HTML-Elements. In unserem Test crawlte Google nur <a>– und <div>-Elemente, nicht aber <p>– und <button>-Elemente.
Für uns eher erstaunlich war, dass Google sämtliche Links ignoriert, die auf externen JS-Dateien beruhen. Wir haben einige Möglichkeiten der Implementation externer Skripte ausprobiert, keine einzige brachte einen Crawling-Erfolg. Das ist darum bemerkenswert, weil JS-Links heute in aller Regel mittels externer Skripte umgesetzt werden. Sobald der JavaScript-Code in das HTML verschoben wurde, spielte es dann aber keine Rolle mehr, wo er platziert wurde, ob innerhalb des Anchor/Div-Elements oder ausserhalb in einem <script>-Element. In beiden Fällen folgte Google den Links.
Unser Fazit
Als Fazit nehmen wir aus diesem Test mit, dass nicht alles, was Google über die Funktions-/Verhaltensweise des eigenen Crawlers sagt, für bare Münze genommen werden sollte. Um auf der sicheren Seite zu sein, halten wir uns im Rahmen unserer SEO-Beratung trotzdem an solche Vorgaben. Wer es aber genau wissen möchte, muss es testen. Und genau an diesem Punkt steht man beim Thema JS-Links und Crawler leider vor einem Problem. Denn das wohl meist verwendete Crawling-Tool Screaming Frog, das ansonsten sehr zuverlässig ist, konnte keinem einzigen JS-Link in unserem Test folgen.
Un wie sieht es mit Ihrer Suchmaschinenoptimierung aus?
Falls Sie Unterstützung im SEO-Bereich brauchen, kontaktieren Sie unser SEO-Team für Auskünfte bezüglich eines SEO Audits oder einer Relaunch-Begleitung. Oder melden Sie sich direkt über unser Kontaktformular.